Опубликован 63-й выпуск рейтинга 500 самых высокопроизводительных компьютеров мира. В 63 редакции рейтинга кластеры, занимавшие в прошлом рейтинге первые пять мест, сохранили свои позиции:
Первое место занимает кластер Frontier, размещённый в Ок-Риджской национальной лаборатории Министерства энергетики США. Кластер насчитывает 8.7 миллиона процессорных ядер (CPU AMD EPYC 64C 2GHz, ускоритель AMD Instinct MI250X) и обеспечивает производительность 1.206 экзафлопса. В качестве операционной системы применяется HPE Cray OS (редакция SUSE Linux Enterprise Server 15).
Второе место занимает кластер Aurora, развёрнутый в Аргоннской национальной лаборатории Министерства энергетики США. По сравнению с прошлой редакцией рейтига кластер нарастил число процессорных ядер (CPU Xeon CPU Max 9470 52C 2.4GHz, ускоритель Intel Data Center GPU Max) с 4.8 до 9.2 млн. Производительность при этом выросла с 585 петафлопс до 1.012 экзафлопса. В качестве операционной системы в Aurora используется SUSE Linux Enterprise Server 15 SP4.
Третье место в рейтинге занимает кластер Eagle запущенный в этом году компанией Microsoft для облака Azure. Кластер содержит 2 млн процессорных ядер (CPU Xeon Platinum 8480C 48C 2GHz) и демонстрирует пиковую производительность в 561 петафлопс. Программное обеспечение кластера базируется на Ubuntu 22.04.
На четвёртом месте находится кластер Fugaku, размещённый в Институте физико-химических исследований RIKEN (Япония). Кластер построен с использованием процессоров ARM (158976 узлов на базе SoC Fujitsu A64FX, оснащённых 48-ядерным CPU Armv8.2-A SVE 2.2GHz). Fugaku обеспечивает производительность 442 петафлопса и работает под управлением Red Hat Enterprise Linux.
Пятое место занимает кластер LUMI, размещённый в Европейском суперкомпьютерном центре (EuroHPC) в Финляндии и обеспечивающий производительность 379 петафлопс. Кластер построен на той же платформе HPE Cray EX235a, что и лидер рейтинга, но включает 2.2 млн процессорных ядер (AMD EPYC 64C 2GHz, ускоритель AMD Instinct MI250X, сеть Slingshot-11). В качестве операционной системы применяется HPE Cray OS.
Шестое место занял новый кластер Alps, запущенный в Швейцарском национальном суперкомпьютерном центре. Кластер насчитывает 1305600 процессорных ядер NVIDIA Grace 72C 3.1GHz и обеспечивает производительность 270 петафлопсов.
Что касается отечественных суперкомпьютеров, то созданные компанией Яндекс кластеры Червоненкис, Галушкин и Ляпунов опустились с 36, 58 и 64 мест на 42, 69 и 79 места. Данные кластеры созданы для решения задач машинного обучения и обеспечивают производительность 21.5, 16 и 12.8 петафлопса соответственно. Кластеры работают под управлением Ubuntu 16.04 и оснащены процессорами AMD EPYC 7xxx и GPU NVIDIA A100: кластер Chervonenkis насчитывает 199 узлов (193 тысячи ядер AMD EPYC 7702 64C 2GH и 1592 GPU NVIDIA A100 80G), Galushkin - 136 узлов (134 тысячи ядер AMD EPYC 7702 64C 2GH и 1088 GPU NVIDIA A100 80G), Lyapunov - 137 узлов (130 тысяч ядер AMD EPYC 7662 64C 2GHz и 1096 GPU NVIDIA A100 40G).
Развёрнутый Сбербанком кластер Christofari Neo опустился с 67 на 83 место. Christofari Neo работает под управлением NVIDIA DGX OS 5 (редакция Ubuntu) и демонстрирует производительность 11.95 петафлопса. Кластер насчитывает более 98 тысяч вычислительных ядер на базе CPU AMD EPYC 7742 64C 2.25GHz и поставляется с GPU NVIDIA A100 80GB. Второй кластер Сбербанка (Christofari) за полгода сместился с 119 на 142 место в рейтинге.
В рейтинге также остаются ещё два отечественных кластера: Lomonosov 2 - сместился с 370 на 406 место (в 2015 году кластер Lomonosov 2 занимал 31 место, а его предшественник Lomonosov в 2011 году - 13 место) и MTS GROM - сместился с 433 на 472 место. Таким образом, число отечественных кластеров в рейтинге не изменилось и, как шесть месяцев назад, составляет 7 систем (для сравнения в 2020 году в рейтинге было 2 отечественные системы, в 2017 году - 5, а в 2012 году - 12).
Наиболее интересные тенденции:
Распределение по количеству суперкомпьютеров в разных странах:
США: 171 (161 - полгода назад). Суммарная производительность оценивается в 34.2% всей производительности рейтинга (полгода назад - 32.8%);
Китай: 80 (104). В сумме китайские кластеры генерируют 16% от всей производительности (полгода назад - 20.8%);
В рейтинге операционных систем, используемых в суперкомпьютерах, c ноября 2017 года остаётся только Linux;
Распределение по дистрибутивам Linux (в скобках - 6 месяцев назад):
42.4% (44.6%) используют системы на базе Linux, но не детализируют дистрибутив;
16.8% (12.6%) - RHEL;
9.4% (11%) CentOS;
9.2% (9.6%) - Cray Linux;
8.4% (7.8%) - Ubuntu;
4.4% (4.4%) - SUSE;
3% (2%) - Rocky Linux;
1.2% (1%) - Alma Linux;
0.2% (0.2%) - Amazon Linux;
0.2% (0.2%) - Scientific Linux.
Минимальный порог производительности для вхождения в Top500 за 6 месяцев составил 2.13 петафлопса (полгода назад - 2.02 петафлопса). Шесть лет назад лишь 272 кластера показывали производительность более петафлопса, семь лет назад - 138). Для Top100 порог вхождения вырос с 7.89 до 9.46 петафлопса, а для Top10 - с 94.64 до 121.4 петафлопса.
Суммарная производительность всех систем в рейтинге за 6 месяцев возросла с 7 до 8.2 экзафлопсов (четыре года назад было 1.650 экзафлопса, а шесть лет назад - 749 петафлопсов). Система, замыкающая нынешний рейтинг, в прошлом выпуске находилась на 457 месте.
Общее распределение по количеству суперкомпьютеров в разных частях света выглядит следующим образом:
181 суперкомпьютер находится в Северной Америке (171 - полгода назад), 157 в Европе (143), 147 в Азии (169), 9 в Южной Америке (10), 5 в Океании (6) и 1 в Африке (1).
В качестве процессорной основы лидируют CPU Intel - 62.8% (полгода назад было 67.9%), на втором месте AMD 31.4% (28%), на третьем IBM Power - 1.2% (было 1.4%).
17.8% (полгода назад 21.4%) всех используемых процессоров имеют 24 ядра, 22% (21%) - 64 ядра, 9% (10.6%) - 20 ядер, 9.4% (7.4%) - 32 ядра, 5.4% (6.2%) - 16 ядер, 5.6% (6%) - 18 ядер, 5.2% (5.2%) - 28 ядер, 5.8% (5%) - 48 ядер, 4.4% - 56 ядер, 2.2% (3%) - 12 ядер. Суммарное число процессорных ядер во всех кластерах рейтинга за полгода увеличилось с 106.3 млн до 114.6 млн.
196 из 500 систем (полгода назад - 185) дополнительно используют ускорители или сопроцессоры, при этом в 142 (155) системах задействованы чипы NVIDIA, в 14 (25) - AMD, в 1 (2) - Intel Xeon Phi, в 4 - Intel DataCenter GPU, в 1 (1) - Matrix-2000.
Среди производителей кластеров на первом месте закрепилась компания Lenovo - 32.6% (полгода назад 33.8%), на втором месте компания Hewlett-Packard Enterprise - 22.4% (20.6%), на третьем месте компания EVIDEN - 9.8% (9.6%), далее следуют Dell EMC 6.8% (6.4%), Inspur - 4.4% (6.8%), NVIDIA 4.4% (3.6%), NEC 2.8% (2.4%), Fujitsu 2.8% (2.4%), MEGWARE 1.4% (1.4%), Microsoft Azure - 1.4% (1.2%), Penguin Computing - 1.4% (1.2%), Sugon 1% (1.8%), IBM 1% (1.2%), Huawei 0.4% (0.4%), Intel 0.4%.
InfiniBand применяется для связи узлов в 47.8% (полгода назад 43.8%) кластеров, Ethernet используется в 39% (41.8%) кластеров, Omnipath - 6.4% (6.6%). Если рассматривать суммарную производительность, то системы на базе InfiniBand охватывают 39.2% (41.4%) всей производительности Top500, а Ethernet - 48.5% (44%).
В ближайшее время ожидается публикация нового выпуска альтернативного рейтинга кластерных систем Graph 500, ориентированного на оценку производительности суперкомпьютерных платформ, связанных с симулированием физических процессов и задач по обработке больших массивов данных, свойственных для таких систем. Рейтинги Green500, HPCG (High-Performance Conjugate Gradient) и HPL-AI объединены с Top500 и отражаются в основном рейтинге Top500.
Энди Ритгер (Andy Ritger), возглавляющий разработку драйверов для Unix-подобных ОС в компании NVIDIA, ответил на вопросы, заданные в связи с переводом проприетарных драйверов NVIDIA на использование по умолчанию открытых модулей ядра Linux на системах с GPU на базе микроархитектур, начиная с Turing.
На вопрос о достижении паритета в функциональности открытых и проприетарных драйверов представитель NVIDIA ответил, что в выпуске драйверов 560 открытые модули ядра будут примерно соответствовать по функциональности проприетарным модулям. Из ограничений отмечается невозможность использования механизма динамического управления энергопотреблением RTD3 (Run Time D3) с открытыми модулями ядра на старых поколениях GPU, предшествующих Ampere (в проприетарных модулях дополнительно поддерживаются GPU на микроархитектуре Turing).
Возможности открытых и проприетарных модулей, связанные с инициализацией GPU и управлением энергопотреблением, будут достаточно близки в драйверах NVIDIA 560, и со временем работа по достижению полного паритета в этом направлению будет продолжаться. В выпуске 560 в открытых модулях также будут решены некоторые давние проблемы, например, связанные с использованием VRR (Variable Refresh Rate) на ноутбуках.
NVIDIA не планирует добиваться включения открытых модулей в основной состав ядра Linux.
На вопрос о поддержке открытых драйверов Nouveau и NVK представитель NVIDIA ответил, что для рабочего применения компания рекомендует использовать проприетарные драйверы и отдельно поставляемые открытые модули ядра. Компания ранее предпринимала попытки предоставления разработчикам nouveau и nvk документации на чипы и аппаратные интерфейсы NVIDIA и передавала отдельные патчи, но предоставленная помощь достаточно скромна, чтобы называть её поддержкой.
На вопрос о возможности поддержки в открытом драйвере Nouveau закрытых компонентов NVIDIA, работающих в пространстве пользователя, таких как CUDA, AI, RT/PT, DLSS и Optix, указано, что пока такой возможности нет и данные компоненты не могут работать при использовании модуля ядра nouveau. Будет ли это возможно в будущем пока не ясно.
Отмечено, что с nouveau также пока невозможно использовать возможности, связанные с настройкой и мониторингом (nvapi/nvidia-smi). При этом осуществлённая в прошлом смена лицензии на определения API nvapi позволила проектам wine и proton подготовить собственные реализации некоторых элементов nvapi, используемых в играх.
На вопрос об участии сотрудников NVIDIA в разработке nouveau, указано, что подобное участие пока незначительно, но некоторые работники уже вносят свой вклад в разработку Nouveau и участвуют в обсуждениях.
NVIDIA не собирается предоставлять открытые модули ядра для старых GPU, предшествующих поколению Turing. Пользователям Volta и более старых GPU следует продолжать использовать проприетарные модули.
На вопрос о планах компании по открытию компонентов стека драйверов для GPU, работающего в пространстве пользователя, отвечавший на вопрос сотрудник NVIDIA заявил, что не слышал о подобных планах.
Решение по использованию открытых модулей по умолчанию объясняется желанием упростить тестирование и снизить издержки, возникающие из-за необходимости повторного тестирования открытых и закрытых модулей.
Мэйнтейнер, обеспечивающий сборку для Debian пакетов с менеджерами паролей KeePassXC, перешёл на поставку максимально урезанной версии программы, в которой оставлена только базовая функциональность, необходимая для безопасного хранения паролей на локальной системе. Расширенные функции, среди которых возможность сетевого взаимодействия, код для управления через IPC, компоненты для интеграции с web-браузерами, функции авто-ввода паролей и код для поддержки ключей Yubikey, удалены из стандартного пакета keepassxc, что объясняется избавлением от излишней функциональности, которая увеличивает поверхность атаки и потенциально может негативно влиять на безопасность и конфиденциальность.
Для пользователей, которым необходима полная версия KeePassXC, предложен отдельный пакет keepassxc-full, включающий все предлагаемые в исходной версии расширенные возможности. Урезанный пакет размещён в репозиториях Debian sid (unstable) и testing вместо старого полного пакета с тем же именем, что вызваловозмущение некоторых пользователей, которые после обновления столкнулись с отсутствием привычной функциональности и восприняли изменение как сбой. Недовольные изменением предлагают мэйнтейнеру KeePassXC в Debian вернуть исходный вариант пакета, а урезанную версию разместить под именем keepassxc-minimal.
С критикой принятого решения также выступил разработчик KeePassXC, который отметил, что пользователи связывают пропадание функциональности с основным проектом и обращаются с жалобами к разработчикам KeePassXC, а не к мейнтейнеру пакета в Debian. Изменение может негативно сказаться на репутации KeePassXC и привести к лишней нагрузке на участников проекта. Кроме того, поднят вопрос о том, насколько правомерно распространять пакет с сохранением названия проекта, но с кардинальным отличием функциональности от базовой сборки, предоставляемой основными разработчиками.
В обсуждении сторонники изменения указывают на то, что каждый включённый плагин потенциально приводит к дополнительному риску наличия уязвимостей или внедрения бэкдора. Кроме того, отмечается, что урезанный пакет размещён только в репозиториях unstable и testing, предназначенных для тестирования, а не в стабильных релизах дистрибутива.
Разработчики KeePassXC пояснили, что применение термина плагины к удалённым дополнительным возможностям некорректно, так как это встроенная функциональность, которая по умолчанию отключена, но может быть активирована в настройках пользователем. Упоминание избавления от внешних библиотек так же отмечаются как беспочвенное, так как код для поддержки Yubikey больше не завязан на внешней библиотеке libyubikey и все необходимые для его работы компоненты поставляются в основной кодовой базе KeePassXC.
После двух месяцев разработки Линус Торвальдс представил релиз ядра Linux 6.9. Среди наиболее заметных изменений: модуль dm-vdo для дедупликации и сжатия блочных устройств, режим прямого доступа к файлам в FUSE, поддержка создания pidfd для отдельных потоков, механизм BPF-токенов, поддержка Rust на системах ARM64, перевод драйвера ФС Ext2 в разряд устаревших, удаление старого драйвера NTFS, поддержка механизма Intel FRED.
В новую версию принято 15680 исправлений от 2106 разработчиков,
размер патча - 54 МБ (изменения затронули 11825 файлов, добавлено 687954 строк кода, удалено 225344 строк). В прошлом выпуске было 15641 исправление от 2018 разработчиков, размер патча - 44 МБ.
Около 42% всех представленных в 6.9 изменений связаны с драйверами устройств, примерно 17% изменений имеют отношение к обновлению кода, специфичного для аппаратных архитектур, 13% связано с сетевым стеком, 7% - с файловыми системами и 4% c внутренними подсистемами ядра.
Дисковая подсистема, ввод/вывод и файловые системы
В Device Mapper (DM) добавлен новый обработчик dm-vdo (virtual data optimizer), позволяющий на базе существующих блочных устройств реализовать виртуальное блочное устройство, обладающее такими возможностями, как дедупликация повторяющихся данных, сжатие данных, исключение пустых блоков и увеличения размера блочного устройства по мере появления необходимости (thin provisioning). Указанные возможности реализуются на уровне блочного устройства и не зависят от используемой файловой системы (например, при помощи dm-vdo можно реализовать автоматическое объединение дублирующихся данных и хранение информации в сжатом виде для любых ФС). Поддерживается применение dm-vdo для физических хранилищ, размером до 256TB, и создание логических томов, размером до 4PB. Для управления разделами vdo рекомендуется использовать lvm. Технология VDO разработана компанией Permabit и открыта после её поглощения Red Hat в 2017 году.
В подсистеме FUSE, применяемой для реализации файловых систем в пространстве пользователя, добавлена начальная реализация режима "passthrough", позволяющего напрямую на уровне ядра получать данные файлов, минуя процесс, работающий в пространстве пользователя, что позволяет в некоторых ситуациях существенно повысить производительность. Например, FUSE-реализации ФС, работающие в режиме только для чтения и разграничивающие доступ к файлам, могут отдавать содержимое файлов из исходной ФС без их передачи в процесс FUSE.
В категорию устаревших (deprecated) переведён драйвер с реализацией файловой системы Ext2. В качестве причины упоминается поддержка в драйвере только 32-разрядных счётчиков времени в inode, которые переполнятся 19 января 2038 года. Вместо драйвера ext2 предлагается использовать драйвер ext4, который поддерживает работу с файловой системой Ext2 и полностью совместим с ней, но при этом может использовать в ext2-разделах временные метки, не подверженные проблеме 2038 года, если ФС создана с inode, размером более 255 байт (в драйвере ext2 32-разрядные счётчики времени использовались независимо от размера inode).
Удалён старый драйвер файловой системы NTFS, на смену которому начиная с выпуска 5.15 пришёл новый драйвер NTFS3. Поставка в ядре двух драйверов с реализацией NTFS признана нецелесообразной, с учётом того, что старый драйвер не обновлялся уже много лет, находится в плачевном состоянии и может работать только в режиме чтения.
В файловые системы zonefs и hugetlbfsдобавлена поддержка маппинга идентификаторов пользователей примонтированных файловых систем, применяемого для сопоставления файлов определённого пользователя на примонтированном чужом разделе с другим пользователем в текущей системе.
В NFSv4 для администраторов предоставлена возможность очистки состояний открытия и блокировки файлов.
Для файловой системы Ext4 отмечается только исправление ошибок и обновление kunit-тестов.
В Btrfs продолженперевод функций на использование фолиантов страниц памяти (page folios). Добавлены оптимизации для ускорения операций журналирования. Примерно на 6% повышена пропускная способность за счёт сокращения конкуренции блокировок. Исключено выполнение полного повторного сканирования квот, излишнего в некоторых ситуациях.
В exFAT значительно повышена производительность при монтировании с опцией "dirsync", при которой выполнение всех операций обновления каталогов осуществляется только в синхронном режиме.
В F2FS улучшена поддержка зонированных блочных устройств и добавлена возможность использования флагов SEEK_DATA и SEEK_HOLE для сжатых файлов.
В Bcachefs добавлена btree-структура с информацией о дочерних элементах подразделов, которая в будущем будет задействована в API для обхода подразделов. Улучшена проверка структуры каталогов. Улучшен процесс журналирования и повышена производительность при высокой нагрузке на запись. Увеличена эффективность операций Discard.
В файловой системе XFS продолжена работа над реализацией возможности применения утилиты fsck для проверки и исправления выявленных проблем в online-режиме, без отмонтирования файловой системы.
В системный вызов pwritev2() добавлен флаг RWF_NOAPPEND, позволяющий указать смещение для записи, даже если файл был открыт в режиме только добавления данных в конец файла.
Добавлены новые ioctl-команды: FS_IOC_GETUUID - возвращает UUID-идентификатор указанной файловой системы, и FS_IOC_GETFSSYSFSPATH - определяет местоположение в /sys/fs заданной примонтированной ФС.
Файловые системы efs, qnx4 и coda переведены на использование нового API монтирования разделов.
Улучшена реализация операций с файлами, выполняемых в режиме без учёта регистра символов. Повышена производительность за счёт выполнения вначале сравнения с учётом регистра и отката на поиск без учёта регистра. Решены проблемы при монтировании overlayfs поверх каталогов, для которых выставлен режим без учёта регистра символов.
Память и системные сервисы
Реализованаподдержка механизма Intel FRED (Flexible Return and Event Delivery), созданного для повышения эффективности и надёжности доставки информации о низкоуровневых событиях, по сравнению с применяемым ныне механизмом
IDT (Interrupt Descriptor Table). Повышение производительности и сокращение задержек обеспечивается благодаря возвращению событий процессорной инструкцией IRET вместо передачи событий через таблицу IDT. Повышение надёжности достигается из-за раздельной обработки поступления события в контексте ядра и контексте пользователя, защиты от вложенного выполнения NMI и сохранения в расширенном кадре стека всех связанных с исключением регистров CPU.
Добавлена возможность оптимизации доступа к данным отдельных ядер CPU через использования в коде ядра именованных адресных пространств (Named Address Spaces), реализованных в GCC в форме расширения GNU C.
В функцию pidfd_open() добавлен флаг PIDFD_THREAD, позволяющий создавать pidfd для отдельных потоков, а не только использовать pidfd в контексте лидера группы потоков. Также предложена реализация псевдо-ФС для доступа к pidfd через виртуальную файловую систему. В отличие от идентификации процессов при помощи pid, идентификатор pidfd связывается с конкретным процессом и не меняется, в том время как PID после завершения текущего процесса может быть привязан к другому процессу.
В подсистему BPF добавлен механизм BPF-токенов, позволяющий выборочно делегировать программам права доступа к привилегированным BPF-операциям, например, можно предоставить непривилегированному приложению доступ к отдельным подсистемам BPF без предоставления полных прав CAP_BPF.
В подсистему BPF добавлен новый тип разделяемой памяти bpf_arena, определяющий область, доступную для совместного использования программами BPF и процессами в пространстве пользователя.
Добавлена инструкция may_goto, позволяющая организовать работу циклов, которые могут быть прерваны верификатором. Добавлена возможность генерации из BPF-программ произвольных TCP SYN cookie и создания BPF-обработчиков для борьбы с SYN-флудом.
В системе управления памятью реализованаподдержка паралелльной инициализации больших страниц памяти (HugeTLB), которая позволила заметно ускорить процесс загрузки на системах с очень большим объёмом ОЗУ. Например, на системе с 12 ТБ ОЗУ инициализация HugeTLB размером 1GB сократилась с 77 до 18 секунд.
Продолжен перенос изменений из ветки Rust-for-Linux, связанных с использованием языка Rust в качестве второго языка для разработки драйверов и модулей ядра (поддержка Rust не активна по умолчанию, и не приводит ко включению Rust в число обязательных сборочных зависимостей к ядру). Добавлена поддержка использования языка Rust при работе на 64-разрядных процессорах ARM. Осуществлён переход на использование выпуска Rust 1.76. Добавлен макрос 'container_of!'. Вместо нестабильной функциональности 'ptr_metadata' задействован стабильный метод 'byte_sub'. Добавлен модуль 'time' с функцией преобразования времени 'msecs_to_jiffies()'.
В подсистему io_uringдобавлена возможность усечения файлов (ftruncate_file).
Добавлен новый тип рабочих очередей WQ_BH (workqueue Bottom Halves) для асинхронного выполнения кода в контексте программных прерываний, нацеленный на использование вместо устаревших tasklet-ов.
Значительно переработана подсистема работы с таймером, в которой улучшена логика выбора активного ядра CPU для выполнения сработавшего таймера, чтобы не выводить из спящего режима неактивные ядра.
Реализована возможность обновления модели потребления энергии ядра (EM, Energy Model) во время работы, что может использоваться, например, для учёта влияния рабочей температуры на энергетическую эффективность CPU. Значительно повышена производительность функции em_cpu_energy(), которая в тестах на стационарной системе теперь выполняется быстрее в 1.43 раза, а в тесте на плате RockPi 4B - в 1.69 раза.
Добавлена поддержка запуска систем на базе архитектуры ARM64 в режиме LPA2 с 52-разрядным виртуальным адресным пространством.
Для систем ARM64 реализована поддержка непрерывных записей PTE (Page Table Entry), позволяющих повысить производительность за счёт повышения эффективности использования TLB (Translation Lookaside Buffer).
Приняты патчи для повышения производительности подсистемы управления памятью за счёт сокращения возникновения конкурирующих блокировок в vmalloc().
Для архитектуры LoongArch реализован механизм горячего наложения патчей на ядро (live patching), позволяющий применять исправления к ядру без перезагрузки.
Для систем RISC-V реализована поддержка системного вызова membarrier(), обеспечивающего установку барьеров на память для работающих в системе потоков. Добавлены реализации алгоритмов AES-ECB, AES-CBC, AES-CTR, AES-XTS, ChaCha20, GHASH, SHA-256, SHA-384, SHA-512, SM3 и SM4, ускоренные при помощи векторных инструкций RISC-V.
В драйвер amd-pstate, применяемый для управления энергопотреблением на системах с процессорами AMD, добавлена возможность использования информации о приоритетных ядрах CPU (Preferred Core), на которых допускается выставление более высокой частоты, для их первоочередного выбора в планировщике для выполнения приоритетных задач.
Максимальный размер шрифтов, которые допускается использовать в консоли fbcon увеличен до 64x128, что позволяет сформировать комфортное отображение текста на экранах 4k.
Добавлена настройка USB_DEFAULT_AUTHORIZATION_MODE, позволяющая изменить применяемый по умолчанию режим авторизации, используемый при подключении USB-устройств и определяющий будет ли система сразу использовать подключённое устройство: 0 - требуется активация из пространства пользователя, 1 (по умолчанию) - все устройства можно использовать сразу и 2 - активация не требуется для внутренних устройств.
Подняты требования к версии LLVM/Clang, которую можно использовать для сборки ядра. Для сборки теперь требуется как минимум выпуск LLVM 13.0.1 (ранее поддерживалась сборка в LLVM 11+).
В механизм "User trace events", позволяющий создавать события трассировки из пользовательских процессов для отслеживания активности в пространстве пользователя, добавлена поддержка экспорта сведений о событии в различных форматах (USER_EVENT_REG_MULTI_FORMAT).
В механизм трассировки вызова функций добавлена возможность отслеживания состояния входящих аргументов функции при трассировке выхода из функции. Значения оператора return теперь можно сопоставить с аргументами, использованными при вызове функции.
В утилиту perf добавлена поддержка режима агрегирования вывода "cluster" ("perf stat -a --per-cluster") для объединения статистики разделяемых ресурсов. Реализована возможность задействования библиотеки libcapstone для дизассемблирования процессорных инструкций ("perf script -F disasm"). Проведены оптимизации потребления памяти при выполнении команд perf report' и 'perf annotate'.
Виртуализация и безопасность
Добавлена защита от уязвимости RFDS (Register File Data Sampling) в процессорах Intel Atom, позволяющей извлечь остаточную информацию из регистровых файлов (RF, Register File) процессора, которые используются для совместного хранения содержимого регистров во всех задачах на том же ядре CPU. Для блокирования уязвимости требуется обновление микрокода и использование инструкции VERW для очистки содержимого микроархитектурных буферов в момент возвращения из ядра в пространство пользователя. Для включения защиты при загрузке ядра можно указать флаг "reg_file_data_sampling=on". Информация о подверженности уязвимости и наличии необходимого для защиты микрокода можно оценить в файле "/sys/devices/system/cpu/vulnerabilities/reg_file_data_sampling".
Добавлена базовая поддержка защиты гостевых систем при помощи расширения AMD SEV-SNP (Secure Nested Paging), обеспечивающего безопасную работу с вложенными таблицами страниц памяти и защищающего от атак "undeSErVed" и "SEVerity" на процессоры AMD EPYC, позволяющих обойти механизм защиты AMD SEV (Secure Encrypted Virtualization). В KVM необходимые для использования SNP изменения планируются добавить в ветке 6.10.
Модули с реализацией технологий IMA (Integrity Measurement Architecture) и ЕVM (Extended Verification Module) переведены на использование фреймворка LSM (Linux Security Modules), что без потери функциональности позволило заметно упростить код, объединить дублирующуюся функциональность и задействовать доступные через LSM типовые возможности. Модуль IMA предназначен для проверки целостности компонентов операционной системы по цифровым подписям и хэшам. Модуль EVM позволяет защитить расширенные атрибуты файлов (xattrs) от атак, направленных на нарушение их целостности (EVM не позволит совершить offline-атаку, при которой злоумышленник может изменить метаданные, например, загрузившись со своего накопителя).
Переделаны для большей совместимости с 32-разрядными окружениями системные вызовы lsm_list_modules(), lsm_get_self_attr() и lsm_set_self_attr(), предназначенные для вывода списка загруженных LSM-модулей (Linux Security Modules) и получения/выставления атрибутов LSM-модуля. Изменение нарушает обратную совместимость, но так как новые системные вызовы были добавлены в прошлом выпуске ядра и пока не используются в приложениях, Линус Торвальдс посчитал, что изменение допустимо.
Предпринята попытка возобновленияиспользования механизма UBSAN (Undefined Behavior Sanitizer). Сутьпроблемы в том, что компиляторы по разному обрабатывают целочисленные переполнения знаковых и беззнаковых типов. Знаковые переполнения и переполнения указателей относятся к категории неопределённого поведения, а беззнаковые переполнения отсекаются по модулю
2n с сохранением только младших битов результата ("wrap-around") и не подпадают под неопределённое поведение. Чтобы исключить ситуации с возникновением неопределённого поведения ядро собирается с опцией "-fno-strict-overflow", которая приводит к использованию "wrap-around" для всех целочисленных переполнений. GCC и Clang не могут нормально диагностировать некоторые проблемы при использовании флага "-fno-strict-overflow" и включение UBSAN нацелено на проведение совместной с разработчиками компиляторов работы по устранению возникающих ложных срабатываний и выявления целочисленных переполнений в местах, в которых отсутствуют явные проверки.
Для проверки возможных переполнений в ядре используются конструкции вида "var + offset < var" (например, "if (pgoff + (size > PAGE_SHIFT) < pgoff){..}"), которые завязаны на сборку с флагом "-fno-strict-overflow" и не охватывают весь код, в котором потенциально может возникнуть переполнение. Проблема в том, что при использовании UBSAN подобные проверки приводили к выводу большого числа ложных предупреждений, и из-за этого в 2021 году UBSAN пришлось отключить. В обновлённой реализации предложено использовать специальные аннотации __signed_wrap и __unsigned_wrap, а также готовые макросы с проверками add_would_overflow(a, b) и add_wrap(a, b), позволяющие отделить предусмотренное разработчиками использования целочисленных переполнений от возникновения случайных переполнений, способных привести к уязвимостям. Предложение более масштабной переделки ядра с введением дополнительных определений типов отвергнуто Линусом Торвальдсом.
Сетевая подсистема
В сетевой подсистеме проведена работа по снижению возникновения конкурирующих блокировок ("lock contention", попытка получить блокировку, удерживаемую другим потоком). Сокращено использования блокировок RTNL.
Добавлена возможность включения поддержки активного полинга сокетов (busy polling) в контексте отдельных вызовов epoll. Размер пула и параметры бюджета могут выставляться отдельно от системных параметров по умолчанию.
Реализована структура net_hotdata для повышения эффективности кэширования наиболее часто используемых переменных сетевой конфигурации.
В MPTCP добавлена поддержка установки для сокетов опции TCP_NOTSENT_LOWAT, позволяющей ограничить размер буфера отправки. В API для сокетов MPTCP добавлена поддержка индентификаторов сети ("network ID"), дающих возможность использовать на одном хосте несколько непересекающихся сетей MPTCP.
В IPSec добавлена поддержка перенаправления ICMP-сообщений с информацией об ошибках (RFC 4301).
Ускорен процесс сканирования маршрутов с истекшим временем жизни.
Ускорена работа XDP, благодаря более жёсткому избеганию выделения больших блоков памяти.
Добавлена возможность прикрепления метаданных к сообщениям netconsole.
В Netfilter разрешено определение из пространства пользователя таблиц, которые привязываются к управляющему фоновому процессу и не удаляются автоматически после завершения пользовательского приложения.
В nftables ускорено добавление элементов в set-наборы с объединёнными диапазонами.
Оборудование
В драйвере i915 продолженаработа по реализации поддержки чипов Intel LunarLake (Xe 2). Добавлены новые PCI-идентификаторы для устройств на базе чипов Intel Arrow Lake и Alder Lake N. Для Displayport добавлена поддержка туннелинга (DP tunneling) и выделения пропускной способности (bandwidth allocation). Для всех платформ включён режим fastboot, отключающий лишние переключения видеорежимов во время загрузки. Добавлена поддержка отладочного вывода в привязке к отдельным устройствам.
В драйвере AMDGPU проведена подготовка к реализации поддержки GPU AMD RDNA3.5 и RDNA4. Добавлена поддержка ATHUB 4.1, LSDMA 7.0, JPEG DPG, IH 7.0, HDP 7.0, VCN 5.0, SMU 13.0.6, NBIO 7.11, SDMA 6.1, MMHUB 3.3, DCN 3.5.1, NBIF 6.3.1, VPE 6.1.1 и фреймворка RAS ACA. В модуль ядра добавлен параметр freesync_video для включения экспериментальной поддержки оптимизации воспроизведения видео с использованием технологии адаптивной синхронизации FreeSync (по умолчанию FreeSync для видео на уровне драйвера теперь отключён, так как KDE и GNOME реализовали собственные методы адаптивной синхронизации частоты кадров).
В драйвере Nouveau код управления экраном переведён на использование функции kmemdup().
Продолженаработа над drm-драйвером (Direct Rendering Manager)
Xe для GPU на базе архитектуры Intel Xe, которая используется в видеокартах Intel семейства Arc и интегрированной графике, начиная с процессоров Tiger Lake.
Добавлен DRM-драйвер для чипов Mediatek MT8188 VDOSYS1.
Связанные с видеоподсистемами настройки ядра перенесены в секцию CONFIG_VIDEO.
В драйвер xpad добавлена поддержка геймпадов Snakebyte и ASUS ROG RAIKIRI. В подсистему HID (Human Interface Device) добавлена поддержка
клавиатур, мышей и геймпадов от компании Samsung, использующих Bluetooth.
Rockchip - Pine64 PineTab2, QNAP TS433 NAS, игровые консоли Powkiddy RGB10MAX3, Anbernic RG-ARC S и RG-ARC D, платы Toybrick TB-RK3588X и Theobroma Systems RK3588-Q7.
Allwinner - Sipeed Longan Pi 3H (Allwinner H618), Remix Mini PC (Allwinner H64).
Qualcomm - Samsung Galaxy Tab 4 10.1 LTE (SM8550, Snapdragon 8 Gen 2), Samsung Galaxy Core Prime, Samsung Galaxy Grand Prime (MSM8916).
Amlogic - Freebox Pop Player (IPTV).
Mediatek - Banana Pi BPI-R4, Xiaomi AX3000T, Radxa NIO 12L, Acelink EW-7886CAX, пять моделей Chromebook.
NVIDIA - два Android-смартфона на чипе Tegra30.
Renesas - плата White Hawk.
Добавлена поддержка SoC Mobileye на базе процессоров MIPS.
Проведён рефакторинг кода звуковой подсистемы ALSA. Добавлена поддержка звуковых систем Microchip SAM9x7, NXP i.MX95, Rockchip RK3308 и Qualcomm WCD939x. В драйвер SoundWire добавлена поддержка ASoC со звуковыми сопроцессорами AMD ACP 6.3, а для систем Intel реализован режим DSPless. Добавлена поддержка дополнительных звуковых кодеков
Cirrus HD. В драйвере virtio улучшено управление звуковыми устройствами.
Добавлена поддержка Ethernet-контроллеров Marvell Octeon PCI Endpoint NIC VF и Intel E825-C 100G.
Одновременно латиноамериканский Фонд свободного ПО сформировал
вариант полностью свободного ядра 6.9 - Linux-libre 6.9-gnu, очищенного от элементов прошивок и драйверов, содержащих несвободные компоненты или участки кода, область применения которых ограничена производителем. В выпуске 6.9 обновлён код чистки блобов в драйверах amdgpu, ath12k, adreno, btusb и r8169. Проведена чистка нового драйвера ptp_fc3. Проведена чистка имён блобов в dts-файлах (devicetree) для архитектуры Aarch64. Устранены проблемы с чисткой драйвера i915, приводившие к зависанию во время инициализации. Внесены изменения, связанные с обработкой блобов, поставляемых в виде шестнадцатеричных дампов.
Компания NVIDIA объявила, что в грядущем выпуске проприетарных драйверов NVIDIA 560 на системах с GPU на базе Turing (GeForce GTX 1600 и RTX 2000) и более новых микроархитектур по умолчанию будут задействованы открытые модули ядра Linux. Код модулей был открыт в 2022 году под лицензиями MIT и GPLv2, и обновляется синхронно с каждым новым выпуском проприетарных драйверов. При этом, несмотря на наличие открытых модулей при установке проприетарных драйверов NVIDIA до сих пор продолжали использоваться проприетарные варианты модулей, основанные на общей кодовой базе с открытыми, но отличающиеся и развивающиеся отдельно.
Открытые и проприетарные модули не могли использоваться одновременно и не могли быть вместе установлены в файловую систему. Открытые модули могут использоваться только с GPU, оснащёнными отдельным микроконтроллером GSP (GPU System Processor), применяемым в таких микроархитектурах, как Turing, Ampere и Ada. В проприетарных модулях, помимо новых GPU, продолжает сохраняться и поддержка старых GPU, не оснащённых GSP, например, GPU на базе микроархитектур Maxwell, Pascal и Volta.
Начиная с выпуска NVIDIA 560 ситуация изменится - для обычных GPU начиная с Turing, а при виртуализации GPU, начиная с Ada, по умолчанию начнут устанавливаться открытые варианты модулей ядра nvidia.ko, nvidia-modeset.ko, nvidia-uvm.ko, nvidia-drm.ko и nvidia-peermem.ko, в ситуациях когда их применение возможно. При желании установить в систему проприетарные модули ядра потребуется указание опции "--kernel-module-type=proprietary" при запуске run-архива с драйверами NVIDIA. В будущем компания NVIDIA планирует прекратить реализацию поддержки новых GPU в проприетарных модулях и сосредоточиться только на развитии открытых.
Доступен выпуск проекта gittuf 0.4, развивающего иерархическую систему верификации содержимого репозиториев Git, позволяющую минимизировать риски в ситуации компрометации отдельных разработчиков, имеющих доступ к репозиторию. Gittuf предоставляет дополнительный слой безопасности к Git и набор утилит для управления ключами всех разработчиков, имеющих доступ к репозиторию, и расстановки правил доступа к веткам, тегам и отдельным файлам. Код проекта написан на языке Go и распространяется под лицензией Apache 2.0. Проект находится на стадии активного развития и имеет качество альфа-выпуска, подходящего для экспериментов, но пока не готового для рабочих внедрений.
Информация и артефакты, обеспечивающие дополнительную верификацию вносимых изменений, хранятся в хранилище объектов Git в отдельном специфичном для gittuf пространстве имён, что позволяет сохранить обратную совместимость с имеющимися инструментами и сервисами, включая GitHub и GitLab. При использовании инструментов без поддержки gittuf, репозиторий остаётся полностью доступен, но ограничена возможность расширенной верификации его целостности. Архитектура gittuf базируется на проверенных элементах фреймворка TUF (The Update Framework), применяемого для защиты процессов формирования обновлений в таких проектах, как Docker, Fuchsia, AGL (Automotive Grade Linux) и PyPI.
Модель верификации в gittuf основана на применении иерархической системы распространения доверия. Корень доверия (root of trust) принадлежит владельцу репозитория, который может генерировать ключи для участников разработки и определять правила, в соответствии с которыми созданные ключи могут применяться. Gittuf позволяет создавать гибкие гранулированные правила, определяющие полномочия каждого разработчика и область репозитория, в которой он имеет возможность вносить изменения. Например, разработчик может быть авторизован для создания тегов, внесения изменений в определённые ветки или изменения только отдельных файлов в репозитории.
Разработчики и вносимые ими изменения идентифицируются по ключам и цифровым подписям. Gittuf позволяет генерировать новые ключи, безопасно распространять ключи, осуществлять периодическую ротацию ключей, отзывать скомпрометированные ключи, управлять списками доступа (ACL) и пространствами имён в Git-репозиториях. Gittuf также выполняет ведение эталонного лога всех изменений (RSL - Reference State Log), целостность и защита от искажения задним числом в котором обеспечивается при помощи древовидной структуры "дерево Меркла" (Merkle Tree) - каждая ветка верифицирует все нижележащие ветки и узлы благодаря древовидному хешированию (имея конечный хеш, пользователь может удостовериться в корректности всей истории операций, а также в корректности прошлых состояний).
Для верификации цифровых подписей коммитов и тегов владелец репозитория формирует и распространяет открытые ключи, которые напрямую ассоциированы с репозиторием. Для противодействия продвижению злоумышленниками изменений, созданных после получения доступа к ключам для формирования цифровых подписей отдельных разработчиков, применяются механизмы отзыва и замены ключей. Ключи имеют ограниченное время жизни и требуют постоянного обновления для защиты от формирования подписи старыми ключами.
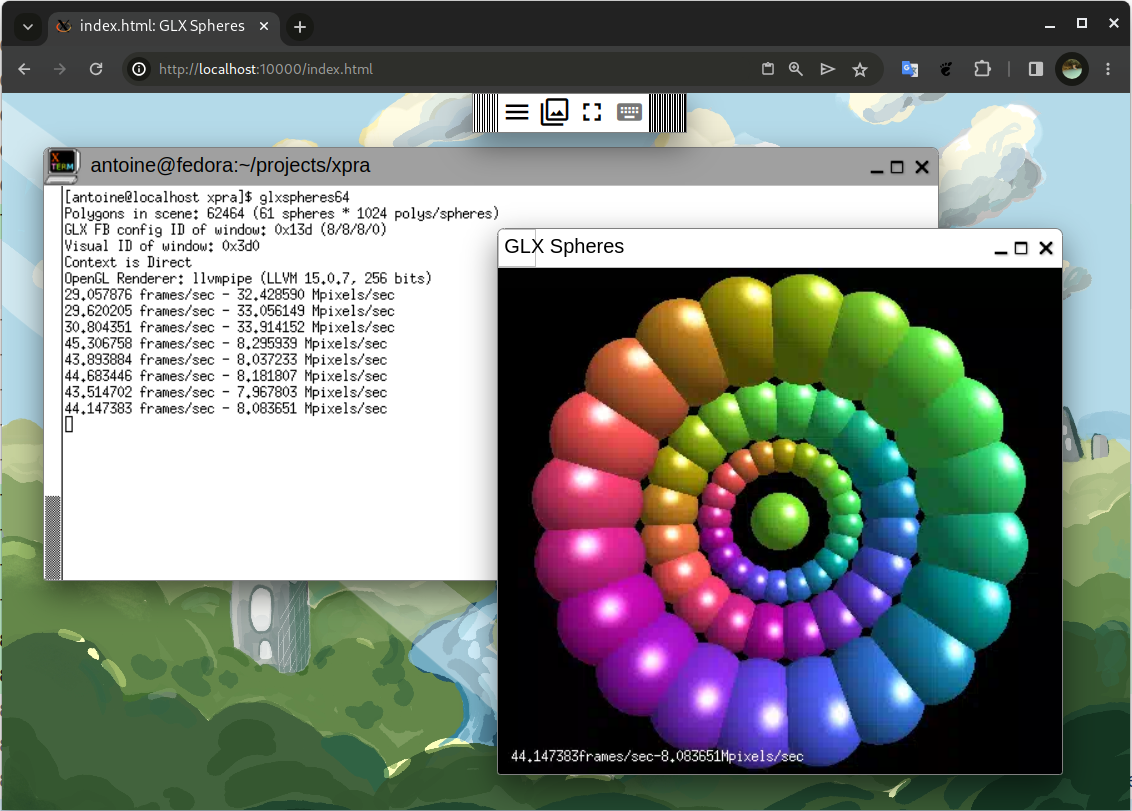
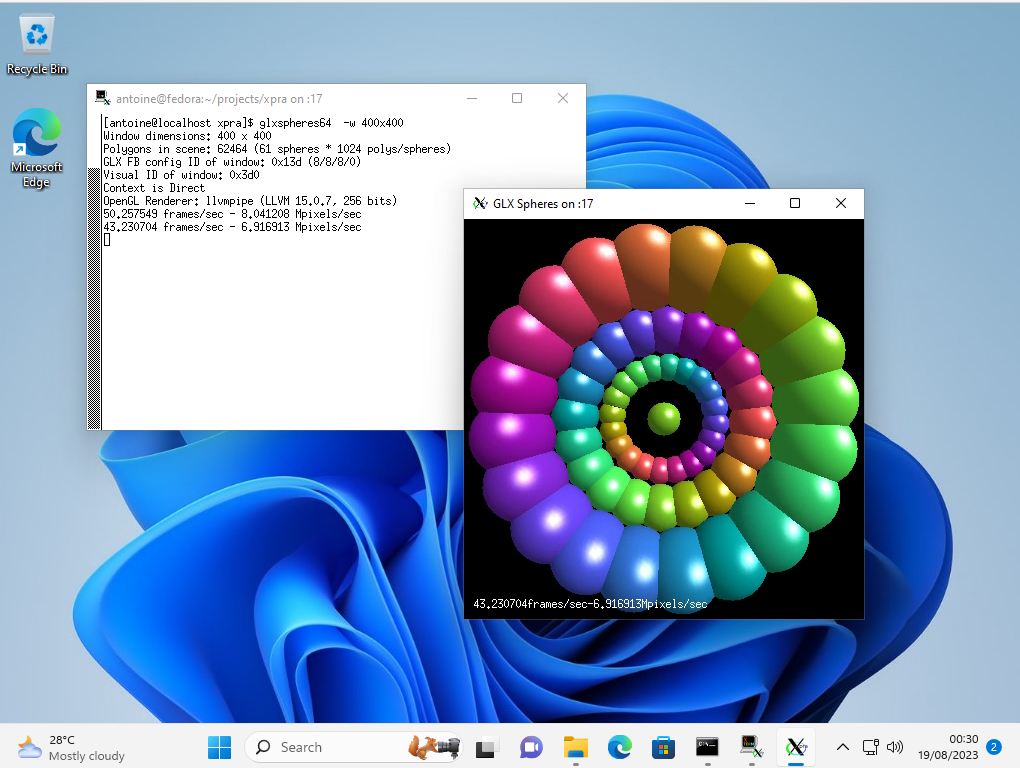
Опубликован выпуск проекта Xpra 6.0, развивающего подобие утилит screen и tmux для работы с графическими приложениями. Xpra позволяет запустить X11-приложения на локальной или удалённой системе, отсоединить сеанс, не завершая выполнение программ, и вернуться к работе с приложениями через какое-то время или продолжить работу с другого хоста (можно начать работу с программой на одной машине и продолжить на другой). Например, Xpra позволяет запустить графическое приложение на внешнем Linux-сервере и отобразить содержимое на экране текущей рабочей станции, функционирующей под управлением Linux, Windows или macOS. Код проекта написан на языке Python и распространяется под лицензией GPLv2+.
Возможно как подключение к имеющимся сеансам рабочего стола, так и создание новых сеансов для организации работы с графическими Linux-программами в окружениях Windows и macOS. Более того, в Xpra имеется встроенный HTML5-клиент, позволяющий подключаться к сеансам через браузер. Кроме доступа к окнам в Xpra реализована поддержка многих сопутствующих возможностей рабочих столов, таких как трансляция звука на удалённую систему, проброс принтеров и web-камер, организация доступа к буферу обмена, поддержка синхронизации состояния системного лотка и уведомлений. Имеются встроенные функции для передачи и синхронизации файлов между системами.
Среди новых возможностей, появившихся в версии Xpra 6.0, можно отметить поддержку архитектуры riscv64, переход на использование базового профиля OpenGL, добавление отдельного клиента для GNOME, реализацию команды "xpra configure" для упрощения настройки параметров Gstreamer, ускорение операций mmap, упрощение быстрого отключения расширенных возможностей для трансляции звука и видео, добавление поддержки виртуальных рабочих столов Windows 10.
Дополнительно можно отметить проект wprs, который развивает аналог Xpra для систем на базе Wayland. Wprs позволяет запускать на локальной или внешней системе приложения, использующие Wayland, и возобновлять работу с ними на других системах. Через привлечение XWayland также обеспечивается возможность запуска приложений, собранных для X11. Для работы на удалённой системе необходимо запустить фоновый процесс wprsd, после чего на той системе можно запускать приложения с других компьютеров, используя команды "wprs run", "wprs detach" и "wprs attach". Код wprs написан на языке Rust и распространяется под лицензией Apache 2.0.
Процесс wprsd включает реализацию композитного сервера Wayland, основанного на библиотеке Smithay и вместо отрисовки на экран выполняющего сериализацию сеанса Wayland для его передачи на другую систему. Сеанс воссоздаётся при помощи утилиты wprsc c реализацией Wayland-клиента на базе Smithay Client Toolkit. Для авторизации доступа и организации канала связи используется SSH. Из ограничений wprs отмечается поддержка только базового протокола Wayland и расширений XDG shell, что, например, не позволяет задействовать аппаратное ускорение отрисовки и dmabuf. Также пока не поддерживается трансляция событий от сенсорных экранов/тачпадов и ограничены возможности интерфейса Drag&drop.
Марк Брукер (Marc Brooker), инженер из компании Amazon Web Services (AWS), разобрал заблуждения, связанные с повышением эффективности передачи мелких сообщений при использовании
алгоритма Нейгла, применяемого по умолчанию в TCP/IP стеке. Рекомендации сводятся к отключению по умолчанию алгоритма Нейгла, что в контексте отдельных приложений можно сделать через выставление опции TCP_NODELAY для сетевых сокетов при помощи вызова setsockopt, что уже давно делается в таких проектах, как Node.js и curl.
Алгоритм Нейгла позволяет агрегировать мелкие сообщения для снижения трафика - приостанавливает отправку новых сегментов TCP до получения подтверждения о приёме ранее отправленных данных. Например, без применения агрегирования при отправке 1 байта, дополнительно отправляется 40 байтов с TCP и IP заголовками пакета. В современных условиях использование алгоритма Нейгла приводит к заметному возрастанию задержек, неприемлемых для интерактивных и распределённых приложений.
Приводится три основных довода в пользу использования по умолчанию опции TCP_NODELAY, отключающей алгоритм Нейгла:
Несовместимость алгоритма Нейгла с оптимизацией "delayed ACK", при которой ACK-ответ направляется не сразу, а после получения ответных данных. Проблема в том, что в алгоритме Нейгла поступление ACK-пакета является сигналом для отправки агрегированных данных, а если ACK-пакет не поступил, отправка выполняется при наступлении таймаута. Таким образом, возникает замкнутый круг и ACK-пакет как сигнал не работает, так как другая сторона не получает данные из-за их накопления на стороне отправителя, а отправитель не отправляет их до таймаута, так как не получает ACK-пакет.
RFC для алгоритма Нейгла принят в 1984 году и он не рассчитан на параметры современных высокоскоростных сетей и серверов в датацентрах, что приводит к возникновению проблем с отзывчивостью. Задержка между отправкой запроса и получением ответа (RTT) в современных сетях составляет 0.5 мс + несколько миллисекунд при обмене данными между датацентрами в одном регионе + до сотни миллисекунд при отправке по всему миру. За эти миллисекунды современный сервер способен выполнить огромный объём работы.
Современные распределённые приложения давно не отправляют единичные байты данных, а агрегирование мелких данных обычно реализуется на уровне приложения. Даже если размер полезных данных составляет считанные байты, то, как правило, фактически размер отправляемой информации существенно возрастает после применения сериализации, использования API-обвязок в JSON и отправки с использованием TLS-шифрования. Экономия 40 байтов становится не столь актуальной.
Опубликован выпуск проекта Nebula 1.9, предлагающего инструментарий для построения защищённых оверлейных сетей, позволяющих объединить территориально разделённые хосты в отдельную изолированную сеть, работающую поверх глобальной сети. Проект предназначен для создания своих собственных оверлейных сетей для любых нужд, например, для объединения корпоративных компьютеров в разных офисах, серверов в разных ЦОД или виртуальных окружений у разных облачных провайдеров. Код написан на языке Go и распространяется под лицензией MIT. Проект основан компанией Slack, развивающей одноимённый корпоративный мессенджер. Поддерживается работа в Linux, FreeBSD, macOS, Windows, iOS и Android.
Узлы в сети Nebula взаимодействуют друг с другом напрямую в режиме P2P - по мере появления необходимости передачи данных между узлами динамически создаются прямые VPN-соединения. Идентичность каждого хоста в сети подтверждается цифровым сертификатом, а подключение к сети требует прохождения аутентификации - каждый пользователь получает сертификат, подтверждающий IP-адрес в сети Nebula, имя и членство в группах хостов. Сертификаты подписываются внутренним удостоверяющим центром, развёртываемым создателем каждой отдельной сети на своих мощностях и применяемым для заверения полномочий хостов, имеющих право подключения к конкретной оверлейной сети, привязанной к удостоверяющему центру.
Для создания аутентифицированного защищённого канала связи в Nebula применяется собственный туннельный протокол, основанный на протоколе обмена ключами Диффи—Хеллмана и шифре AES-256-GCM. Реализация протокола базируется на готовых и проверенных примитивах, предоставляемых фреймворком Noise, который также применяется в таких проектах, как WireGuard, Lightning и I2P. Утверждается, что проект прошёл независимый аудит безопасности.
Для обнаружения других узлов и координации подключении к сети создаются специальные узлы "lighthouse", глобальные IP-адреса которых фиксированы и известны участникам сети. У узлов-участников нет привязки к внешнему IP-адресу, они идентифицируются по сертификатам. Владельцы хостов самостоятельно не могут внести изменения в подписанные сертификаты и в отличие от традиционных IP-сетей не могут притвориться другим хостом простой сменой IP-адреса. При создании туннеля идентичность хоста подтверждается индивидуальным закрытым ключом.
Создаваемой сети выделяется определённый диапазон интранет адресов (например, 192.168.10.0/24) и осуществляется связывание внутренних адресов с сертификатами хостов. Предоставляются различные механизмы для обхода трансляторов адресов (NAT) и межсетевых экранов. Возможна организации маршрутизации через оверлейную сеть трафика сторонних хостов, не входящих в сеть Nebula (unsafe route). Из участников оверлейной сети могут формироваться группы, например, для разделения серверов и рабочих станций, к которым применяются отдельные правила фильтрации трафика.
Поддерживается создание межсетевых экранов для разделения доступа и фильтрации трафика между узлами в оверлейной сети Nebula. Для фильтрации применяются ACL с привязкой тегов. Каждый хост в сети может определять собственные правила фильтрации по хостам, группам, протоколам и сетевым портам. При этом хосты фильтруются не по IP-адресам, а по заверенным цифровой подписью идентификаторам хоста, которые невозможно подделать без компрометации удостоверяющего центра, координирующего работу сети.
В новом выпуске:
Добавлена новая настройка default_local_cidr_any, которая меняет поведение при обработки подсетей "local_ip" в правилах межсетевого экрана для предотвращения необоснованного разрешения трафика к хостам, перечисленным в блоке unsafe_routes. В версии 1.9 настройка выставлена в значение "true", но в следующем выпуске 1.10 будет заменена на значение "fasle", что приведёт к учёту локальных подсетей при применении правил межсетевого экрана к хостам, доступным через небезопасные маршруты (для открытия доступа к таким хостам потребуется обязательное указание local_cidr).
Предоставлен официальный образ для системы Docker, позволяющий быстро развернуть оверлейную сеть на базе Nebula или узел для неё.
Добавлены экспериментальные сборки для архитектуры Loong64.
В фоновый процесс SSH добавлена поддержка аутентификации по сертификатам, заверенным удостоверяющим центром (sshd.trusted_cas). Реализована возможность встраивания хостовых ключей в блок настроек sshd.host_key.
Обеспечена поддержка перезагрузки настроек "tun.unsafe_routes".
Удалена поддержка устаревшей настройки local_range, вместо которой следует использовать preferred_ranges.
Для сборки теперь требуется инструментарий go 1.22. Минимальные требования к версиям Windows повышены до Windows 10 и Windows Server 2016.
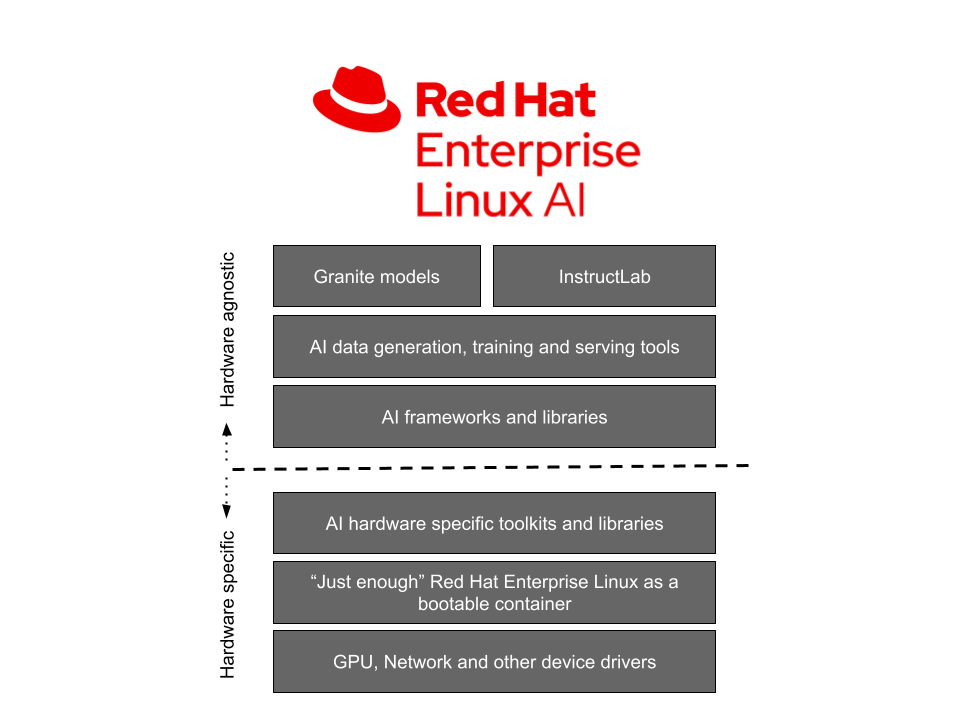
Компания Red Hat представила дистрибутив Red Hat Enterprise Linux AI (RHEL AI), который специально адаптирован для выполнения задач машинного обучения и призван упростить создание серверных решений, использующих большие диалоговые модели. В состав входит подборка инструментов и фреймворков для машинного обучения, а также драйверы для использования различных аппаратных ускорителей AMD, Intel и NVIDIA, и компоненты для задействования возможностей серверов Dell, Cisco, HPE, Lenovo и SuperMicro, оптимизированных для AI-систем.
RHEL AI предназначен для разработки, тестирования и выполнения систем машинного обучения на базе большой языковой модели Granite, открытой компанией IBM под лицензией Apache 2.0, способной учитывать при генерации текста до 4 тысячи токенов и охватывающей 7 миллиардов параметров. Для взаимодействия с моделью Granite в дистрибутив интегрирован открытый инструментарий InstructLab, поддерживающий методологию LAB (Large-scale Alignment for chatBots) для подгонки под свои нужды и оптимизации моделей, а также для добавления дополнительных знаний и реализации новых навыков в предварительно натренированных моделях.
Платформа может применяться для разработки AI-приложения для корпоративных нужд и для внедрения сервисов для генерации контента, создания диалоговых систем и интеграции в приложения виртуальных ассистентов, поддерживающих такие навыки, как возможность отвечать на вопросы на естественном языке, решать математические задачи, генерировать осмысленный текст на заданную тему, составлять краткое изложение содержимого, исправлять ошибки в тексте, выполнять рерайтинг другими словами, помогать в написании кода на различных языках программирования, формировать письма и документы по шаблону.
Кроме того, компания Red Hat представила новый режим для создания и управления системными образами на базе Red Hat Enterprise Linux - "image mode", который позволяет использовать для развёртывания операционной системы инструменты и технологии, применяемые для создания и запуска контейнеров приложений. Новый режим манипулирует монолитными системными образами, формируемыми при помощи инструментария rpm-ostree и обновляемыми атомарно без разбивки на отдельные пакеты.
Сборки могут формироваться в виде образов в форматах OCI (как в Docker), ISO, QCOW2, AMI, VMI и VMDK. Содержимое образа выбирается через редактирование файла Containerfile. Для создания и управления образами могут использоваться стандартные инструменты управления контейнерами, такие как Podman и OpenShift Container Platform. Для установки образов может применяться как штатный инсталлятор Anaconda, так и инструментарий bootc-image-builder, позволяющий сконвертировать образ контейнера в загрузочный дисковый образ. Для обновления загрузочных образов контейнеров, которые поставляются с ядром Linux и способны загружаться по аналогии с обычными сборками системы, применяется инструментарий bootc.
После года разработки опубликован релиз свободного набора компиляторов GCC 14.1, первый значительный выпуск в новой ветке GCC 14.x. В соответствии со схемой нумерации выпусков, версия 14.0 использовалась в процессе разработки, а незадолго до выхода GCC 14.1 уже ответвилась ветка GCC 15.0, на базе которой будет сформирован следующий значительный релиз GCC 15.1.
Значительно расширены возможности для статического анализа кода на языке Си, доступные через опцию "-fanalyzer" (статический анализ для языка С++ пока не доведён до должного вида). Усилен анализ операций со строками и проверка наличия завершающего строку нулевого символа. Добавлено новое предупреждение "-Wanalyzer-infinite-loop" для выявления бесконечных циклов. Добавлена серия предупреждений "-Wanalyzer-tainted-*" для выявления проблем с проверкой входных данных. Расширены возможности предупреждения "-Wanalyzer-out-of-bounds" для выявления переполнений буфера, например, добавлена возможность отображения диаграммы с визуализацией состояния, приводящего к переполнению.
Добавлена новая сборочная опция "--enable-host-pie" для сборки исполняемых файлов компилятора в режиме PIE (Position Independent Executable), а также опция "--enable-host-bind-now" для связывания с опциями "-Wl,-z,now".
Добавлена новая опция "-fhardened", включающая флаги для усиления безопасности (-D_FORTIFY_SOURCE=3
-D_GLIBCXX_ASSERTIONS
-ftrivial-auto-var-init=zero
-fPIE -pie -Wl,-z,relro,-z,now
-fstack-protector-strong
-fstack-clash-protection
-fcf-protection=full).
Добавлена опция "-fharden-control-flow-redundancy" для добавления в конец функций кода для выявления некоторых форм неопределённого поведения, которые потенциально могут привести к нарушению нормального порядка выполнения (control flow) в результате применения эксплоитов, изменяющих хранимые в памяти указатели на функции и передающих управление в середину функций.
Добавлен новый атрибут типов "hardbool", позволяющий переопределить значения, сопоставленные с признаками true и false, для затруднения некоторых видов атак.
Добавлен новый атрибут типов strub для управление обнулением кадров стека с данными функций и переменных после выхода из функции или срабатывания исключения.
Добавлена опция -finline-stringops для включения inline-раскрытия функций memcmp, memcpy, memmove и memset, даже когда это не нужно для оптимизации.
Добавлен новый атрибут функций null_terminated_string_arg(PARAM_IDX) для пометки параметров, которые следует трактовать как строки, заканчивающиеся нулевым символом.
В векторизаторе реализована поддержка векторизации циклов, содержащих выражения "break".
Добавлена начальная поддержка предварительной версии спецификации OpenMP 6.0 (Open Multi-Processing) и продолжена реализация стандартов OpenMP 5.0, 5.1 и 5.2, определяющих API и способы применения методов параллельного программирования на многоядерных и гибридных (CPU+GPU/DSP) системах с общей памятью и блоками векторизации (SIMD).
Улучшена реализация спецификаций параллельного программирования OpenACC 2.7 и 3.2, определяющих средства для выноса операций (offloading) на GPU и специализированные процессоры, такие как NVIDIA PTX.
Для C, C++ и Objective-C реализована поддержка расширений "__has_feature" и "__has_extension", применяемых в Clang.
Реализованы возможности, определённые в будущем Си-стандарте C23, такие как типы "_BitInt (N)" и "unsigned _BitInt (N))". Структуры, объединения и перечисления разрешено определять более одного раза в одной области видимым с одним и тем же содержимым и повторяющимся тегом. Добавлена поддержка заголовочного файла stdckdint.h. Для включения поддержки элементов C23 предложены флаги "-std=c23", "-std=gnu23" и "-Wc11-c23-compat".
Для языка Си добавлено выражение "#pragma GCC novector", отключающее векторизацию анотированных циклов.
Добавлены возможности, связанные со стандартом C++23. Добавлена поддержка механизма "Deducing this", позволяющего использовать в шаблоне параметры с признаком "this" и дающего возможность из функции класса узнать категорию выражения (например, является ли константой), для которого эта функция вызвана. Реализовано требование, в соответствии с которым все функции, вызывающие функции с признаком consteval тоже становятся consteval, т.е. выполняются при компиляции. Ослаблены некоторые требования к "constexpr".
Добавлены возможности, связанные с будущим стандартом C++2с (C++26). Например, предоставлена возможность использования строковых литералов в контексте, в котором они не используются для инициализации массива символов и не попадают в результирующий код, а применяются только во время компиляции для диагностических сообщений и препроцессинга. Добавлена возможность использования сразу нескольких переменных-заполнителей с именем "_" в одной области видимости. Переведено в разряд устаревших выполнение неявных преобразований перечисляемых значений в арифметических вычислениях.
В libstdc++ улучшена поддержка стандартов C++20, C++23 и C++26.
В компиляторе для языка Fortran началась работа над поддержкой стандарта Fortran 2023 (-std=f2023).
Объявлена устаревшей поддержка расширения GCC, позволяющего указывать гибкий элемент-массив (массив неопределённого размера, например, "int b[]") не в самом конце структуры (Flexible Array Members). Массив неопределённого размера в дальнейшем можно будет использовать только в конце структуры.
В бэкенде для архитектуры AArch64 реализована поддержка CPU
Ampere-1B (ampere1b), Arm Cortex-A520 (cortex-a520),
Arm Cortex-A720 (cortex-a720), Arm Cortex-X4 (cortex-x4) и
Microsoft Cobalt-100 (cobalt-100). Для использования в опциях "-mcpu=" и "-mtune=" добавлены новые идентификаторы CPU generic, generic-armv8-a и generic-armv9-a. Добавлена поддержка расширений Arm SME и SME2 (Streaming Matrix Extensions). Реализованы специфичные для
архитектуры AArch64 оптимизации.
В бэкенде для архитектуры ARM добавлена поддержка CPU Cortex-M52 (cortex-m52 в опциях "-mcpu=" и "-mtune=").
В бэкенде генерации кода для GPU AMD Radeon (GCN) реализована поддержка GPU AMD Radeon gfx90c (GCN5), gfx1030, gfx1036 (RDNA2), gfx1100 и gfx1103 (RDNA3). Повышена производительность для устройств AMD серий MI100 и MI200. По умолчанию активирована архитектура устройств gfx900 (Vega).
В бэкенд для архитектуры x86 добавлена поддержка расширений архитектуры набора команд Intel AVX10.1, Intel APX (частично), Intel AVX-VNNI-INT16, Intel SHA512, Intel SM3, Intel SM4, Intel USER_MSR.
Добавлена поддержка CPU AMD на базе ядра Zen 5 (-march=znver5), а также процессоров Intel Clearwater Forest (-march=clearwaterforest), Arrow Lake (-march=arrowlake), Arrow Lake S (-march=arrowlake-s), Lunar Lake (-march=lunarlake) и Panther Lake (-march=pantherlake).
Добавлена опция "-m[no-]evex512" для управления задействованием 512-битных векторов (по умолчанию включается при поддержке AVX512F. Объявлена устаревшей поддержка CPU Intel Xeon Phi.
Расширены возможности бэкендов для платформ LoongArch, AVR и RISC-V.
Расширены возможности вывода диагностики в формате SARIF, основанном на JSON. Формат SARIF можно использовать для получения результатов статического анализа (GCC -fanalyzer), а также для получения сведений о предупреждениях и ошибках.
Переведена в разряд устаревших и будет удалена в следующем релизе GCC поддержка целевых архитектур ia64 и nios2, применяемых в процессорах Intel Itanium и Nios II.
Для кода на языке Си, собираемом с выставлением стандартов новее C89, некоторые выведенные из стандарта С99 конструкции теперь приводят к выводу ошибок, а не предупреждений. Например, среди подобных возможностей неявное использование типа int (-Werror=implicit-int), обращение к необъявленным функциям (-Werror=implicit-function-declaration), неверные названия типов в объявлениях функций (-Werror=declaration-missing-parameter-type), некорректное использование выражения return (-Werror=return-mismatch), использование указателей как чисел (-Werror=int-conversion) и сочетание разных типов указателей (-Werror=incompatible-pointer-types).
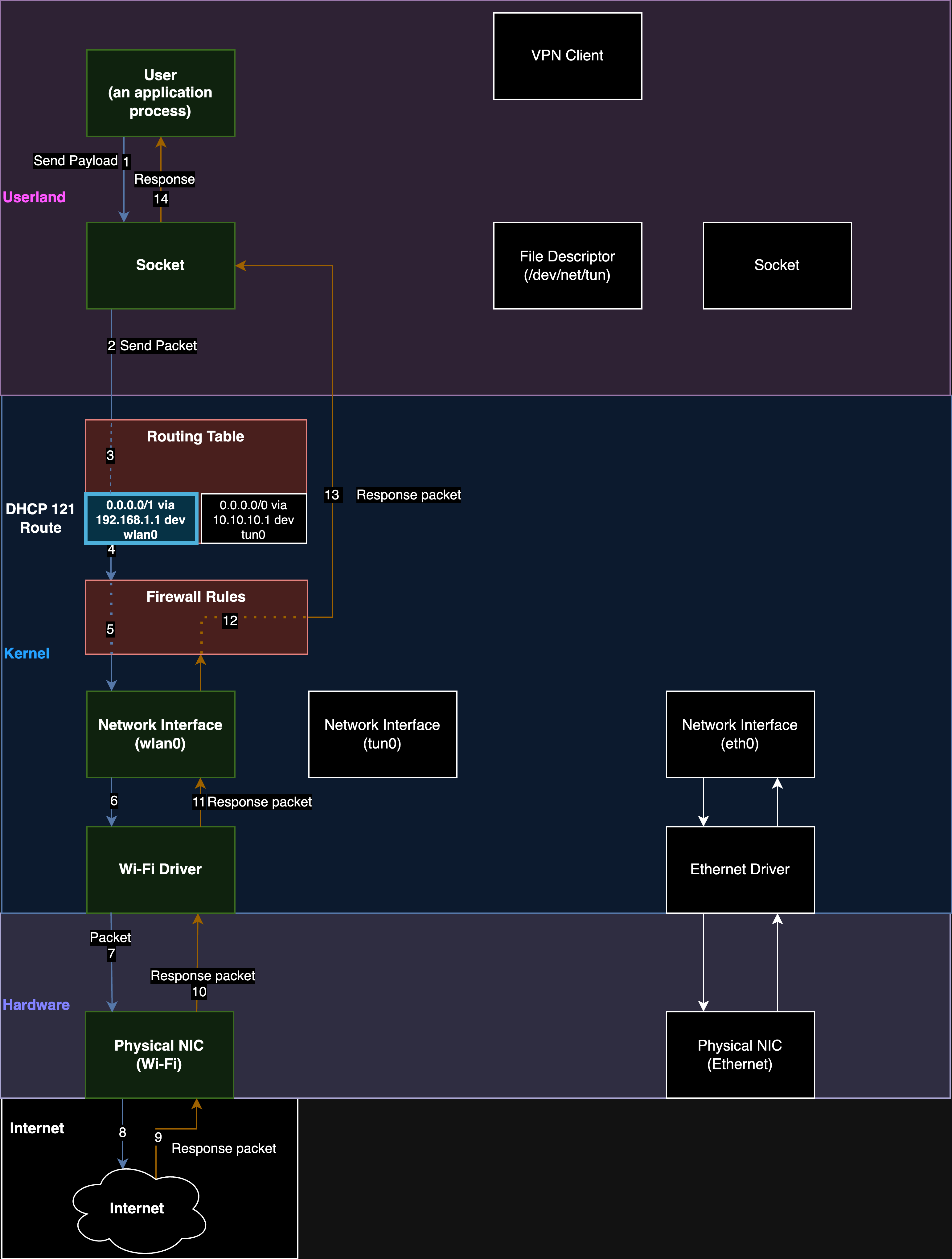
Вниманию публики предложен метод атаки TunnelVision, позволяющий при наличии доступа к локальной сети или контроля над беспроводной сетью, осуществить перенаправление на свой хост трафика жертвы в обход VPN (вместо отправки через VPN, трафик будет отправлен в открытом виде без туннелирования на систему атакующего). Проблеме подвержены любые VPN-клиенты, не использующие изолированные пространства имён сетевой подсистемы (network namespace) при направлении трафика в туннель или не выставляющие при настройке туннеля правила пакетного фильтра, запрещающие маршрутизацию VPN-трафика через имеющиеся физические сетевые интерфейсы.
Суть атаки в том, что атакующий может запустить свой DHCP-сервер и использовать его для передачи клиенту информации для изменения маршрутизации. В частности, атакующий может воспользоваться предоставляемой в протоколе DHCP опцией 121 (RFC-3442, принят в 2002 году), предназначенной для передачи сведений о статических маршрутах, для внесения изменений в таблицу маршрутизации на машине жертвы и направления трафика в обход VPN. Перенаправление осуществляется через выставления серии маршрутов для подсетей с префиксом /1, которые имеют более высокий приоритет, чем применяемый по умолчанию маршрут с префиксом /0 (0.0.0.0/0), соответственно трафик вместо выставленного для VPN виртуального сетевого интерфейса, будет направлен через физический сетевой интерфейс на хост атакующего в локальной сети.
Атака может быть осуществлена в любых операционных системах, поддерживающих 121 опцию DHCP, включая Linux, Windows, iOS и macOS, независимо от используемого протокола VPN (Wireguard, OpenVPN, IPsec) и набора шифров. Платформа Android атаке не подвержена, так как не обрабатывает опцию 121 в DHCP. При этом атака позволяет получить доступ к трафику, но не даёт возможность вклиниться в соединения и определить содержимое, передаваемое с использованием защищённых протоколов уровня приложений, таких как TLS и SSH, например, атакующий не может определить содержимое запросов по HTTPS, но может понять к каким серверам они отправляются.
Для защиты от атаки можно запретить на уровне пакетного фильтра отправку пакетов, адресованных в VPN-интерфейс, через другие сетевые интерфейсы; блокировать DHCP-пакеты с опцией 121; использовать VPN внутри отдельной виртуальной машины (или контейнера), изолированной от внешней сети, или применять специальные режимы настройки туннелей, использующие пространства имён в Linux (network namespace). Для экспериментов с проведением атаки опубликован набор скриптов.
Можно отметить, что идея локального изменения маршрутизации не нова и ранее обычно использовалась в атаках, нацеленных на подмену DNS-сервера. В похожей атаке TunnelCrack, в которой перенаправление трафика осуществлялось через замену шлюза по умолчанию, проблема затрагивала все проверенные VPN-клиенты для iOS, в 87.5% VPN-клиентов для macOS, 66.7% для Windows, 35.7% для Linux и 21.4% для Android. В контексте VPN и DHCP метод также упоминался ранее, например, ему посвящён один из докладов на прошлогодней конференции USENIX 2023 (исследование показало, что 64.6% из 195 протестированных VPN-клиентов подвержены атаке).
Для подстановки маршрутов ранее также предлагалось использовать специально оформленный USB-брелок, симулирующий работу сетевого адаптера, который при подключении к компьютеру при помощи DHCP объявляет себя в качестве шлюза. Кроме того, при наличии контроля за шлюзом (например, при подключении жертвы к контролируемой атакующим беспроводной сети) была разработана техника подстановки пакетов в туннель, воспринимаемых в контексте сетевого интерфейса VPN.
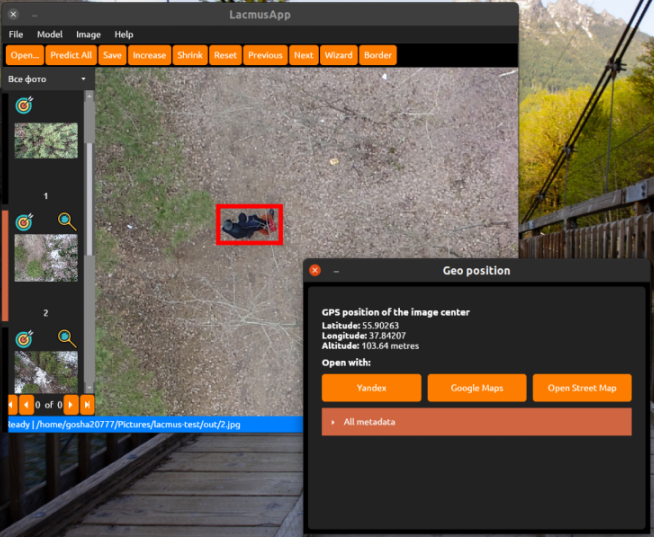
Состоялся релиз программы Lacmus 1.0 "Furious Vaporization". Проект представляет собой кроссплатформенное решение для автоматизации поиска и спасения пропавших людей с помощью алгоритмов компьютерного зрения и AI. Проект написан на языке C# и распространяется под лицензией GPLv3, а его разработка велась более пяти лет в тесном контакте с сообществом поисково-спасательных отрядов.
Программный комплекс Lacmus позволяет осуществлять автоматизированный поиск по фотографиям, отснятым с БПЛА, помогает выявлять снимки, на которых присутствует потерявшийся человек, и предоставляет пользователю координаты искомого объекта. Работа программы основана на применении нейронных сетей и алгоритмов компьютерного зрения для распознавания людей на снимках с БПЛА, что позволяет увеличить эффективность поисковых операций, сократить время на их проведение и, в конечном итоге, повысить вероятность успешного спасения потерявшихся людей.
Программа поддерживает различные операционные системы, включая Linux, Windows и macOS, и обеспечивает возможность использования различных типов графических ускорителей, таких как GPU NVIDIA, Intel, AMD, NPU и TPU, для оптимизации работы нейронных сетей. Для пользовательского интерфейса используется кроссплатформенный фреймворк AvaloniaUI, а для запуска моделей машинного обучения применяется ONNX Runtime и легковесная версия TensorFlow.
Модели компьютерного зрения распространяются в виде подключаемых модулей, которые можно скачать в каталоге ML-моделей в окне настроек программы, притом каждый такой плагин содержит в себе необходимые зависимости, избавляя конечного пользователя от установки дополнительных зависимостей и библиотек. В качестве основных архитектур нейронных сетей используются YOLOv5 и RetinaNet.
Проект развивается при поддержке ассоциации Lacmus Foundation, которая занимается открытыми исследованиями в области поиска и спасения пропавших людей. Организация не имеет юридических структур и основана на добровольных началах. Статистика говорит о том, что ежегодно в мире тысячи людей пропадают без вести. Проект Lacmus призван быть лакмусовой бумажкой (за что и получил своё название) в решении этой проблемы, обеспечивая поисковым и спасательным службам современные средства для эффективного выполнения их задач и спасения как можно большего числа жизней.
На конференции LibrePlanet 2024 состоялась церемония награждения, на которой объявлены лауреаты ежегодной премии "Free Software Awards 2023", учрежденной Фондом свободного ПО (FSF) и присуждаемой людям, внесшим наиболее значительный вклад в развитие свободного ПО, а также социально значимым свободным проектам. Победители получили памятные пластинки и грамоты (премия FSF не подразумевает денежного вознаграждения).
Премию за продвижение и развитие свободного ПО получил Бруно Хайбле (Bruno Haible), сопровождающий проект Gnulib, развивающий коллекцию типового кода для совместного использования в различных пакетах GNU. Бруно также является одним из создателей CLISP, реализации языка LISP, и участником разработки GNU M4, Automake, libiconv и gettext.
В номинации, вручаемой проектам, принёсшим значительную пользу обществу и способствовавшим решению важных социальных задач, награда присуждена французскому проекту code.gouv.fr, который помогает государственным учреждениям в переходе на использование свободного и открытого ПО, а также занимается сопровождением процессов открытия кода проектов, разработанных в госучреждениях.
В номинации за выдающийся вклад нового участника в развитие свободного ПО, которая присуждается новичкам, первый вклад которых показал заметную приверженность движению свободного ПО, премию получил
Ник Логоззо (Nick Logozzo), студент Университета штата Нью-Йорк в Стони-Бруке, развивающий набор приложений Nickvision для GNOME, написанных на C# с использованием GTK 4 и libadwaita. Среди проектов Ника программа Parabolic для загрузки видео/аудио из Web и просмотра YouTube без выполнения кода на JavaScript (обвязка над утилитой yt-dlp), система тэгирования музыки Tagger, система управления финансами Denaro, визуализатор звука
Cavalier и FlatpakGenerator, генератор Flatpak-файлов для проектов на C#.
2019 Джим Мейринг (Jim Meyering), с 1991 года занимается сопровождением пакета GNU Coreutils, один из основных разработчиков autotools и создатель Gnulib.
2018 Дебора Николсон (Deborah Nicholson), директор по взаимодействию с сообществом в организации Software Freedom Conservancy;
2017 Карен Сэндлер (Karen Sandler), директор правозащитной организации Software Freedom Conservancy;
2016 Александре Олива (Alexandre Oliva), бразильский популяризатор и разработчик свободного ПО, основатель Латиноамериканского Фонда СПО, автор проекта Linux-Libre (полностью свободный вариант ядра Linux);
2015 Вернер Кох (Werner Koch), создатель и основной разработчик инструментария GnuPG (GNU Privacy Guard);
2014 Себастьян Жодонь (Sébastien Jodogne), автор Orthanc, свободного DICOM-сервера для обеспечения доступа к данным компьютерной томографии;
2013 Мэтью Гаррет (Matthew Garrett), один из разработчиков ядра Linux, входящий в технический совет организации Linux Foundation, внёсший значительный вклад в обеспечение загрузки Linux на системах с UEFI Secure Boot;
2012 Фернандо Переc (Fernando Perez), автор IPython, интерактивной оболочки для языка Python;
2011 Юкихиро Мацумото (Yukihiro Matsumoto), автору языка программирования Ruby. Юкихиро уже на протяжении 20 лет участвует в развитии проектов GNU, Ruby и других открытых проектов;
2010 Роб Савуа (Rob Savoye), лидер проекта по созданию свободного Flash-плеера Gnash, участник разработки GCC, GDB, DejaGnu, Newlib, Libgloss, Cygwin, eCos, Expect, основатель компании Open Media Now;
2009 Джон Гилмор (John Gilmore), один из основателей правозащитной организации Electronic Frontier Foundation, создатель легендарного списка рассылки Cypherpunks и иерархии Usenet-конференций alt.*. Учредитель компании Cygnus Solutions, первой начавшей оказывать коммерческую поддержку для решений на базе свободного ПО. Основатель свободных проектов Cygwin, GNU Radio, Gnash, GNU tar, GNU UUCP и FreeS/WAN;
2008 Wietse Venema (известный эксперт в области компьютерной безопасности, создатель таких популярных проектов, как Postfix, TCP Wrapper, SATAN и The Coroner's Toolkit);
2007 Harald Welte (архитектор мобильной платформы OpenMoko, один из 5 основных разработчиков netfilter/iptables, мантейнер подсистемы пакетной фильтрации Linux ядра, активист движения свободного программного обеспечения, создатель сайта gpl-violations.org);
2006 Theodore T'so (разработчик Kerberos v5, файловых систем ext2/ext3, известный хакер Linux ядра и участник группы, разработавшей спецификацию IPSEC);
2005 Andrew Tridgell (создатель проектов samba и rsync);
2004 Theo de Raadt (руководитель проекта OpenBSD);
2003 Alan Cox (вклад в разработку Linux ядра);
2002 Lawrence Lessig (популяризатор открытого ПО);
Состоялся выпуск децентрализованной платформы для организации видеохостинга и видеовещания PeerTube 6.1. PeerTube предлагает независимую от отдельных поставщиков альтернативу YouTube, Dailymotion и Vimeo, использующую сеть распространения контента на базе P2P-коммуникаций и связывания между собой браузеров посетителей. Наработки проекта распространяются под лицензией AGPLv3.
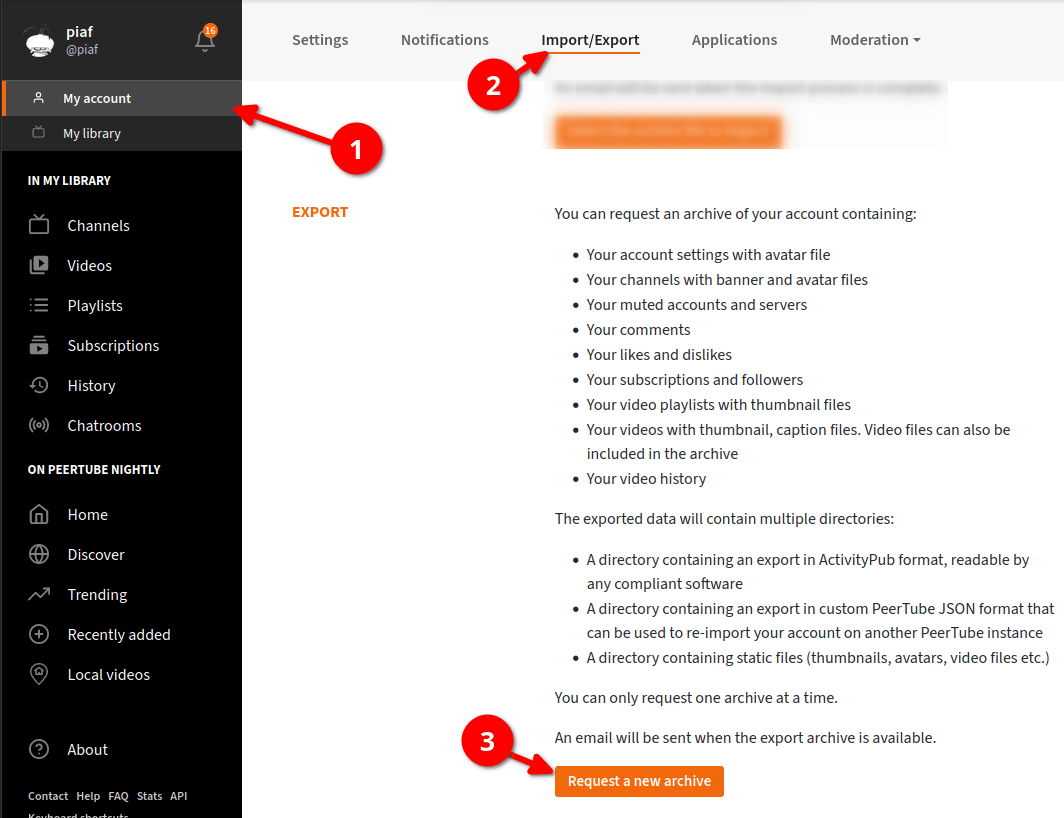
Предоставлена возможность экспорта всех данных, связанных с учётной записью, среди которых видео, каналы и настройки. Данные экспортируются в форме одного загружаемого архива, который может использоваться для импорта на другой системе.
Обеспечено сохранение оригинального файла с видео, изначально загруженного в PeerTube и затем перекодированного в другие форматы (раньше после перекодирования исходный файл удалялся). Добавленная возможность позволяет использовать PeerTube для хранения своих видеоархивов, без деления на локальные и внешние видео.
Добавлена возможность создания баннера для своего сервера, который будет отображаться на станице о сервере, на странице входа, при регистрации и при поиске в каталоге JoinPeerTube, а также на страницах, в которых используется тег "<peertube-instance-banner>". Аналогично добавлена возможность добавления аватара, видимо в мобильном приложении и на домашней странице сервера.
Задержка перед началом подсчёта просмотров видео снижена с 30 до 10 секунд по аналогии с Vimeo, Instagram, TikTok и Mux. При подсчёте просмотров теперь учитывается не только IP-адрес, но и идентификатор браузера. На странице со статистикой просмотров обеспечено отображение данных в привязке к отдельным регионам, а не только к странам.
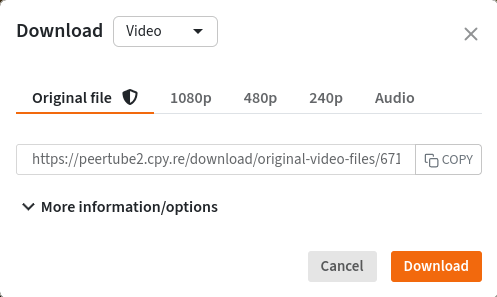
Для упрощения доступа к субтитрам в видеопроигрыватель добавлена отдельная кнопка "СС" (7 на скриншоте ниже), при нажатии на которую будет включён показ субтитров на последнем выбранном языке. Также предоставлена возможность смены языка через меню с настройками (8 на скриншоте).
В интерфейсе пользователя предоставлена возможность загрузки видео напрямую из библиотеки.
Для администратора добавлены возможности сортировки пользователей и видео по размеру данных, сохранённых на диске.
Устранены две уязвимости в реализации протокола ActivityPub. Первая уязвимость приводит к утечке данных, связанных с приватными видео, таких как комментарии и лайки. Вторая уязвимость касается некорректного управления доступом к объектам JSON-LD, загруженным из федеративной сети.
Платформа PeerTube изначально была основана на применении BitTorrent-клиента WebTorrent, запускаемого в браузере и использующего технологию WebRTC для организации прямого P2P-канала связи между браузерами. Позднее вместо WebTorrent был задействован протокол HLS (HTTP Live Streaming) в связке с WebRTC, позволяющий адаптивно управлять потоком в зависимости от полосы пропускания. Для объединения разрозненных серверов с видео в общую федеративную сеть, в которой посетители участвуют в доставке контента и имеют возможность подписки на каналы и получения уведомлений о новых видео, задействован протокол ActivityPub. Предоставляемый проектом web-интерфейс построен с использованием фреймворка Angular.
Федеративная сеть PeerTube образуется как содружество связанных между собой небольших серверов хостинга видео, на каждом из которых имеется свой администратор и могут быть приняты свои правила. Каждый сервер с видео выполняет роль BitTorrent-трекера, на котором размещены учётные записи пользователей данного сервера и их видео. Идентификатор пользователя формируются в форме "@имя_пользователя@домен_сервера". Передача данных при просмотре осуществляется непосредственно из браузеров других посетителей, просматривающих контент.
Если видео никто не просматривает, отдача организуется сервером, на который изначально загружено видео (используется протокол WebSeed). Помимо распределения трафика между пользователями, просматривающими видео, PeerTube также позволяет узлам, запущенным авторами для первичного размещения видео, кэшировать видео других авторов, формируя распределённую сеть не только из клиентов, но и из серверов, а также обеспечивая отказоустойчивость. Имеется поддержка потокового вещания (live streaming) с доставкой контента в режиме P2P (для управления стримингом могут использоваться типовые программы, такие как OBS).
Для начала вещания через PeerTube пользователю достаточно загрузить на один из серверов видеоролик, описание и набор тегов. После этого ролик станет доступен во всей федеративной сети, а не только с сервера первичной загрузки. Для работы с PeerTube и участия в распространении контента достаточно обычного браузера и не требуется установка дополнительного ПО. Пользователи могут отслеживать активности в выбранных видеоканалах, подписавшись на интересующие каналы в федеративных социальных сетях (например, в Mastodon и Pleroma) или через RSS. Для распространения видео с использованием P2P-коммуникаций пользователь также может добавить на свой сайт специальный виджет со встроенным web-плеером.
В настоящее время для размещения контента функционирует 1126 серверов, поддерживаемых разными добровольцами и организациями. Если пользователя не устраивают правила размещения видео на определённом сервере PeerTube, он может подключиться к другому серверу или запустить свой собственный сервер. Для быстрого развёртывания сервера предоставляется преднастроенный образ в формате Docker (chocobozzz/peertube).







{kind=link}